Simian Luo 骆思勉
|
I am Simian Luo, 23, currently a second year M.S student in Artificial Intelligence at IIIS (Institute for Interdisciplinary Information Sciences), Tsinghua University (清华交叉信息研究院) advised by Prof. Hang Zhao. Previously, I received my B.E. in Data Science from School of Data Science, Fudan University, advised by Prof. Yanwei Fu.
My research interest focus on Advanced Generative Model, Multi-Modal Generation and LLM Application.
In specfic, I have researched in diffusion model, audio-visual generation, 3D generation, and Augmentated LLM.
|

|
|
|
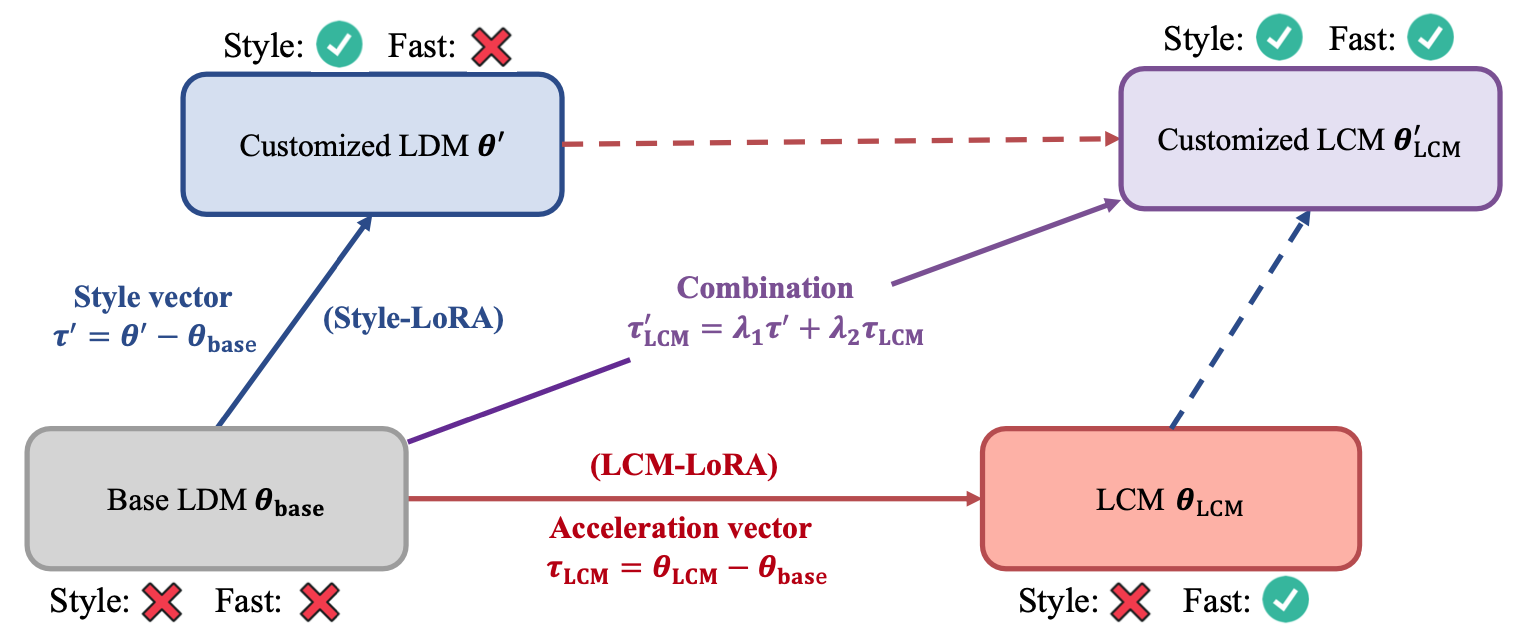
![[NEW]](images/new.png) Follow our latest work: LCM-LoRA: A Universal Stable-Diffusion Acceleration Module. A training-free neural network-based acceleration module that can directly plugged into various finetuned SD and SD LoRAs.!!
Follow our latest work: LCM-LoRA: A Universal Stable-Diffusion Acceleration Module. A training-free neural network-based acceleration module that can directly plugged into various finetuned SD and SD LoRAs.!!
|
|
|
Follow our latest work: Latent Consistency Models: Synthesizing High-Resolution Images With Few-Step Inference. The next generation of generative models after latent diffusion models (LDMs) !!
|
|
|
Oral Presentation at CVPR 2023 Sight and Sound Workshop about our latest work:
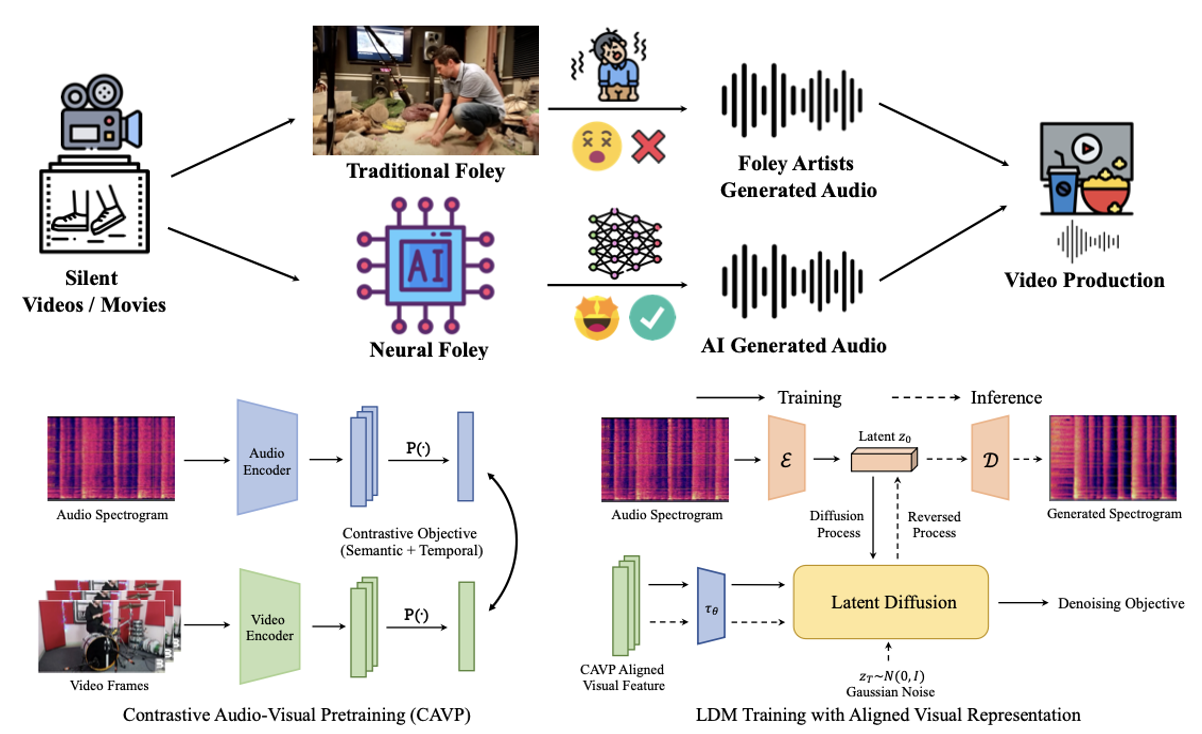
Diff-Foley: Synchronized Video-to-Audio Synthesis with Latent Diffusion Models. |
|
* indicates equal contribution |
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
|
|
| Invited paper talk at Sight and Sound Workshop, CVPR 2023, "Diff-Foley: Synchronized Video-to-Audio Synthesis with Latent Diffusion Models." |
|
|

|

|
| FDU 2018-2022 |
THU 2022 - Present |